import numpy as np
import pandas as pd
from report_utils import ROUNDS, prediction_path, real_results
from tsv_utils import load_country_data
def elo_before(team: str, cutoff) -> float:
"""Team's Elo going into the round (latest rating before the cutoff)."""
return load_country_data(team, end_date=cutoff)["current_team_elo"].iloc[0]
rows = []
for round_key, (fixtures, start_date, _end) in ROUNDS.items():
results_df = real_results(round_key)
if results_df.empty:
continue
pred_df = pd.read_csv(prediction_path("ensemble", round_key), index_col=0)
merged = results_df.merge(pred_df, on=["team_1", "team_2"],
how="inner", suffixes=("_real", "_pred"))
decided = merged[merged["winner_real"] != "Draw"]
cutoff = start_date - pd.Timedelta(days=1)
gaps = [abs(elo_before(t1, cutoff) - elo_before(t2, cutoff))
for t1, t2, _loc in fixtures]
rows.append({
"round": round_key,
"accuracy_all": (merged["winner_real"] == merged["winner_pred"]).mean(),
"accuracy_decided": (decided["winner_real"] == decided["winner_pred"]).mean(),
"draw_share": (merged["winner_real"] == "Draw").mean(),
"elo_gap": float(np.mean(gaps)),
})
phases = pd.DataFrame(rows)
fig, (ax_acc, ax_gap) = plt.subplots(1, 2, figsize=(11, 4.3), dpi=140)
x = np.arange(len(phases))
short_labels = ["MD 1", "MD 2", "MD 3", "R32", "R16"][: len(phases)]
ax_acc.bar(x - 0.19, phases["accuracy_all"], width=0.38,
color="#2e9e5b", alpha=.55, label="all matches")
ax_acc.bar(x + 0.19, phases["accuracy_decided"], width=0.38,
color="#2e9e5b", label="decided matches only")
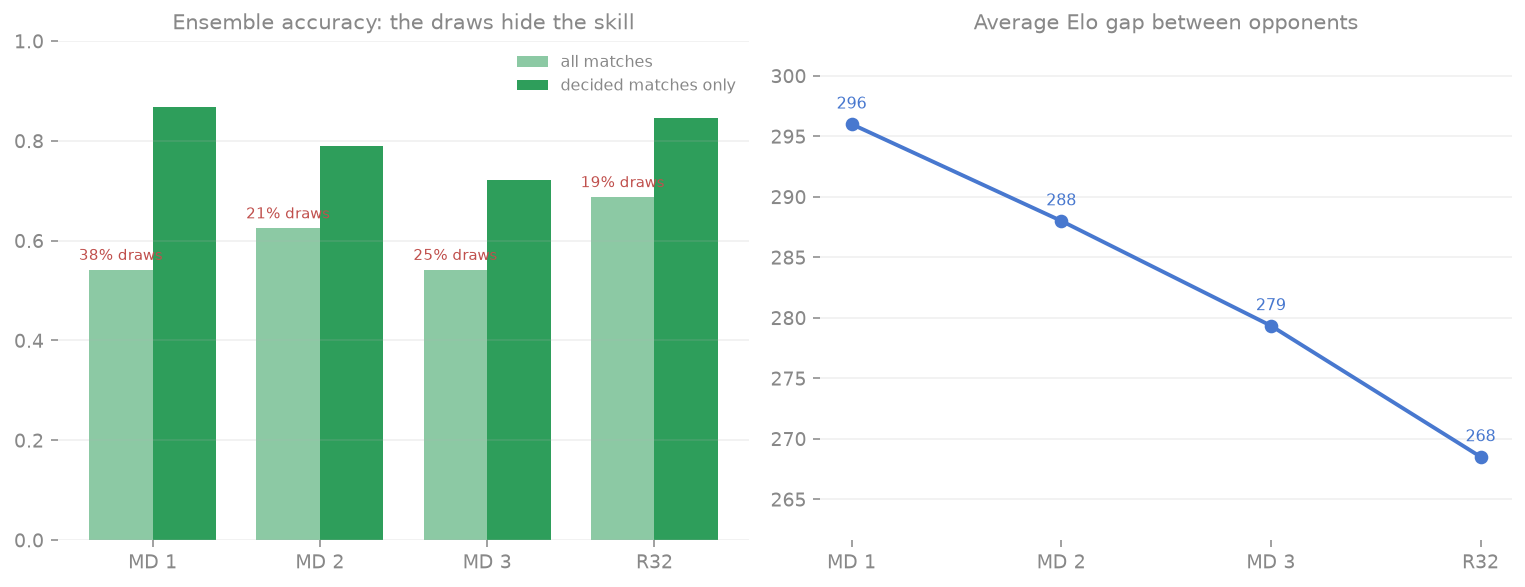
for xi, draw_share, acc_all in zip(x, phases["draw_share"], phases["accuracy_all"]):
ax_acc.annotate(f"{draw_share:.0%} draws", xy=(xi - 0.19, acc_all), xytext=(0, 5),
textcoords="offset points", ha="center",
fontsize=7.5, color="#c0504d")
ax_acc.set_xticks(x, short_labels)
ax_acc.set_ylim(0, 1)
ax_acc.set_title("Ensemble accuracy: the draws hide the skill", color="#888888", fontsize=11)
ax_acc.legend(frameon=False, labelcolor="#888888", fontsize=8)
ax_gap.plot(x, phases["elo_gap"], marker="o", color="#4878cf", linewidth=2)
for xi, gap_value in zip(x, phases["elo_gap"]):
ax_gap.annotate(f"{gap_value:.0f}", xy=(xi, gap_value), xytext=(0, 8),
textcoords="offset points", ha="center", fontsize=8, color="#4878cf")
ax_gap.set_xticks(x, short_labels)
ax_gap.set_title("Average Elo gap between opponents", color="#888888", fontsize=11)
ax_gap.margins(y=.25)
for ax in (ax_acc, ax_gap):
ax.tick_params(colors="#888888")
ax.grid(axis="y", alpha=.2)
for spine in ax.spines.values():
spine.set_visible(False)
ax.patch.set_alpha(0)
fig.patch.set_alpha(0)
fig.tight_layout()
phases.round(3)